Rethinking Discrete Speech Representation Tokens for Accent Generation
|Paper Under Review|
Abstract
Discrete Speech Representation Tokens (DSRTs) have become a foundational component in speech generation. While prior work has extensively studied phonetic and speaker information in DSRTs, how accent information is encoded in DSRTs remains largely unexplored. In this paper, we present the first systematic investigation of accent information in DSRTs. We propose a unified evaluation framework that measures both accessibility of accent information via a novel Accent ABX task and recoverability via cross-accent Voice Conversion (VC) resynthesis. Using this framework, we analyse DSRTs derived from several widely used speech representations. Our results reveal that: (1) choice of layers has the most significant impact on retaining accent information, (2) accent information is substantially reduced by ASR supervision; (3) naive codebook size reduction cannot effectively disentangle accent from phonetic and speaker information.
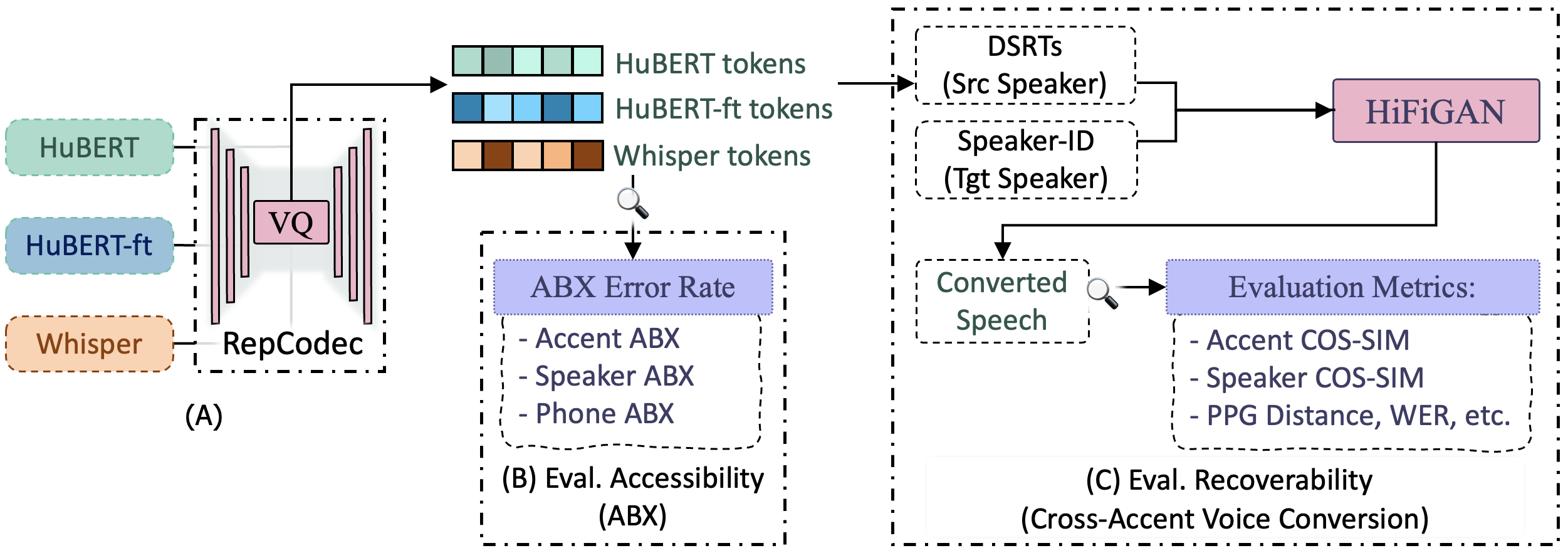
Evaluation Framework
A framework for evaluating the recoverability and accessibility of accent, speaker, and phonetic information in various Discrete Speech Representation Tokens (DSRTs, aka semantic tokens).
Cross-Accent Voice Conversion (Demo)
Controlling accent in speech generation is a challenging task. Using the proposed framework and the findings, we propose DSRT design choices that can effectively disentangle accent information from speaker and phonetic information. We demonstrate the effectiveness of these design choices in a Cross-Accent Voice Conversion task, with potential applications to Zero-Shot TTS or SpeechLMs.
Specifically, We use content tokens to generate accent and voice that are both similar to target speaker, performing Accent-Adaptive Voice Conversion. We use content-accent tokens to generate accent similar to source speaker, but voice similar to target speaker, performing Accent-Preserving Voice Conversion. Both objective and subjective evaluation show superior performance to existing approaches such as Vevo's content and content-style tokens.
Accent-Adaptive Voice Conversion
| Source | Target | Vevo (content) | Proposed (content) | |
|---|---|---|---|---|
|
p311 to p226 utterance 012 |
||||
|
p311 to p228 utterance 024 |
||||
|
p333 to p228 utterance 003 |
Accent-Preserving Voice Conversion
| Source | Target | Vevo (content-style) | Proposed (content-accent) | |
|---|---|---|---|---|
|
p334 to p226 utterance 006 |
||||
|
p333 to p228 utterance 003 |
||||
|
p333 to p225 utterance 009 |
Accent-Adaptive Voice Conversion
| Source | Target | Vevo (content) | Proposed (content) | |
|---|---|---|---|---|
|
p335 to p232 utterance 010 |
||||
|
p326 to p232 utterance 001 |
||||
|
p326 to p232 utterance 011 |
Accent-Preserving Voice Conversion
| Source | Target | Vevo (content-style) | Proposed (content-accent) | |
|---|---|---|---|---|
|
p374 to p228 utterance 021 |
||||
|
p326 to p228 utterance 017 |
||||
|
p326 to p232 utterance 005 |
Accent-Adaptive Voice Conversion
| Source | Target | Vevo (content) | Proposed (content) | |
|---|---|---|---|---|
|
p264 to p225 utterance 024 |
||||
|
p285 to p225 utterance 010 |
||||
|
p284 to p226 utterance 003 |
Accent-Preserving Voice Conversion
| Source | Target | Vevo (content-style) | Proposed (content-accent) | |
|---|---|---|---|---|
|
p265 to p225 utterance 023 |
||||
|
p264 to p232 utterance 021 |
||||
|
p264 to p226 utterance 023 |
Accent-Adaptive Voice Conversion
| Source | Target | Vevo (content) | Proposed (content) | |
|---|---|---|---|---|
|
p248 to p225 utterance 002 |
||||
|
p251 to p225 utterance 003 |
||||
|
p376 to p225 utterance 004 |
Accent-Preserving Voice Conversion
| Source | Target | Vevo (content-style) | Proposed (content-accent) | |
|---|---|---|---|---|
|
p248 to p225 utterance 002 |
||||
|
p251 to p225 utterance 003 |
||||
|
p376 to p225 utterance 004 |