Accent Generation - Challenges and Progress
|Edinburgh Science Festival 2025|
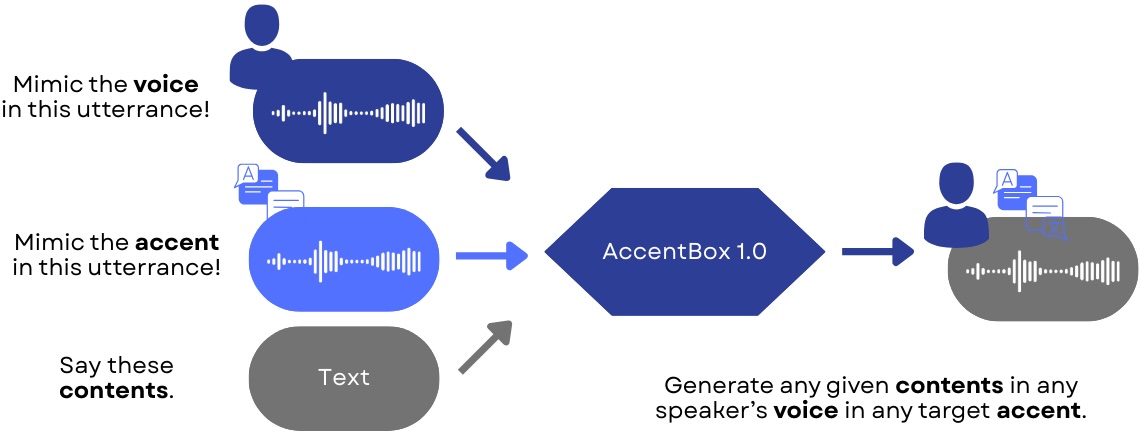
Model Overview
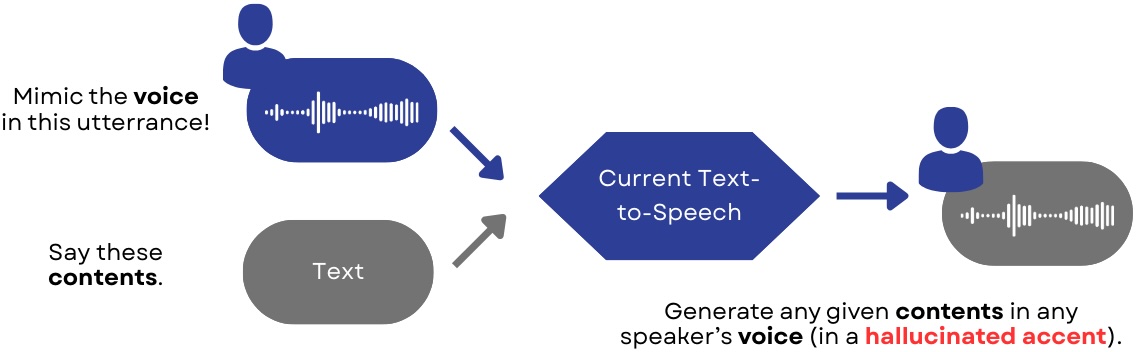
"Betraying" Scottish Accents
Note: "Betraying" is a metaphorical way of saying these systems generate hallucianted accents, misrepresenting the voice identities of Scottish/English users.
We asked two Current TTS systems and our AccentBox, to mimic a Scottish speaker's voice.
Transcription: This is a very common type of bow, one showing mainly red and yellow, with little or no green or blue.
| Text | Current TTS 1 | Current TTS 2 | AccentBox |
|---|---|---|---|
| Well, here's a story for you. | |||
| Sarah Perry was a veterinary nurse who had been working daily at an old zoo in a deserted district of the territory. | |||
| So, she was very happy to start a new job at a superb private practice in North Square near the Duke Street Tower. | |||
| That area was much nearer for her and more to her liking. | |||
| Even so, on her first morning, she felt stressed. |
"Betraying" English Accents
We asked two Current TTS systems and our AccentBox, to mimic an English speaker's voice.
Transcription: This is a very common type of bow, one showing mainly red and yellow, with little or no green or blue.
| Text | Current TTS 1 | Current TTS 2 | AccentBox |
|---|---|---|---|
| Well, here's a story for you. | |||
| Sarah Perry was a veterinary nurse who had been working daily at an old zoo in a deserted district of the territory. | |||
| So, she was very happy to start a new job at a superb private practice in North Square near the Duke Street Tower. | |||
| That area was much nearer for her and more to her liking. | |||
| Even so, on her first morning, she felt stressed. |
Accent Conversion
We asked our AccentBox to generate speech in the English speaker's voice in various accents.
Transcription: This is a very common type of bow, one showing mainly red and yellow, with little or no green or blue.
Then convert to various accents!
| Text | Original English | American | Australian | Irish | Scottish |
|---|---|---|---|---|---|
| Once Sarah had managed to bathe the goose, she wiped her off with a cloth and laid her on her right side. | |||||
| Then Sarah confirmed the vet’s diagnosis. | |||||
| Almost immediately, she remembered an effective treatment that required her to measure out a lot of medicine. | |||||
| Sarah warned that this course of treatment might be expensive - either five or six times the cost of penicillin. | |||||
| I can't imagine paying so much, but Mrs. Harrison - a millionaire lawyer - thought it was a fair price for a cure. |
Difficulty in Evaluation
1. Why Evaluation is Needed?
“In machine learning, it's not just what you build - it's how well you measure it. Without rigorous evaluation, a model is just a guess.”
We heavily rely on human listeners to provide us with high-quality, accurate, and meaningful feedbacks, so that we can build better TTS systems.
2. Vague Feedbacks on Accent
We did a naive listening test and asked listeners to comment on the clues they used to decide which one is better.
These are some of the comments we got. I was not sure how I could use this to meaningfully improve our system.
"very close but flow on accent slightly better here"
"flow more natural like the reference (speech)"
"close but slightly better flow"
"Mixture between American and English accent"
"The speed overall and tone sounds the same (as the reference speech)"
"More accurate speech pattern (than the other candidate speech)"
...
3. A Novel Listening Test Design
Rather than an open-ended text entry box, we gave listeners this highlighting task.
This is what we got in the end. The darker the color, the more listeners selected these parts (as clues for evaluating accent similarity).
